A survey of modern Deep learning based Object Detection Models
1. 简介
目标检测通常是指在图片或视频中对目标物体的边界框以及类别做出精准判断的任务。目标检测包含了两方面的内容:对物体边界框的回归和对已有边界框的物体进行分类。目前目标检测领域在应用到实际生活的过程中,仍然存在以下三个关键问题:
- 类内差异(Intra class variation):在普通现实场景中,出现类内差异的情况非常常见。例如同一种类别的物体可能会出现遮挡、重叠、光照、姿势、视点等变化,而这种外界因素的干扰或者约束,可能会给同一种物体的外观带来巨大的差异,甚至有些物体可能出现非刚性的变形或者旋转、缩放或者模糊等变化。这些上述的原因都将给物体的提取识别带来困难。
- 类别的数量(Number of categories):在一张图片中往往会出现不止一个同一类别的物体,这不光对于检测器的精度要求非常高,并且对数据的标注要求也非常高。
- 效率(Efficiency):目前已有目标检测模型成功应用到实时检测系统里,因此检测的速度也成为了一项重要的评价指标。
目标检测领域正是以解决上述三个难点逐渐发展起来的,现有的优秀目标检测器有非常之多,以经典的一阶段、二阶段检测算法为代表,近几年又兴起了以Transform为基础的无卷积网络。本文将针对目标检测器的显著分类进行介绍。与此同时,本文也将介绍目标检测领域使用广泛的一些评价指标和数据集。
2. 数据集
现有的目标检测数据集主要有以下几类:
1)PASCAL VOC 07/12
The Pascal Visual Object Classes (VOC) 挑战是一项多年的努力,旨在加速视觉感知领域的发展。它开始于2005年,起初只有四个物体类别的分类和检测任务,但这个挑战的两个版本(07和12版本)大多被用作标准基准,其简单信息如下:
07:训练集(5011幅),测试集(4952幅),共计9963幅图,共包含20个种类。下载链接
12:训练集(5717幅),验证集(5823幅),训练集+验证集共计11540幅图,共包含20个种类(main文件夹下)。下载链接
Pascal VOC引入了在0.5 IoU(Intersection over Union)的平均平均精度(mAP)来评估模型的性能。
2)ILSVRC
The ImageNet Large Scale Visual Recognition Challenge (ILSVRC) 是一项从2010年到2017年年度举办的挑战赛。ImageNet作为该挑战赛的官方数据集,是由斯坦福著名教授李飞飞等人创建的,该数据集包含了超过50万张共计200类的目标检测任务图片。且自2010年起,随着比赛的进行,该数据集每年都会进行完善更新,所以下载的时候请注意下载对应年份版本的数据集。
由于该数据集不允许作为商用,完整下载该数据集需要edu邮箱验证,因此只在此放上官网链接,进行注册验证使用。ImageNet官网
如果因为网络原因下载很慢的话,不妨试试这个链接。
3)MS-COCO
The Microsoft Common Objects in Context (MS-COCO) 是著名的挑战赛数据集之一,由微软公司创建提供。该数据集包含超过30万张共计80类的目标检测任务图片,且平均每张图片中包含了3.5个类别,7.7个目标实例,目标的密集度大于其他著名数据集。并且,MS COCO数据集中的图片来自不同的视角。下载链接
与Pascal VOC和ILSVCR不同,它从0.5到0.95分步计算IoU,然后用这10个值的组合作为最终指标,称为Average Precision (AP)。
MS-COCO官网目前无法下载数据集,可以尝试用下面的命令行进行下载:
1 | mkdir coco |
4)Open Image
谷歌的Open Image数据集由920万张图像组成,其中包含190万张图片共计600类的目标检测任务图片。该数据集对Pascal VOC中引入的AP做了一些改变,如忽略未注释的类,对类和其子类的检测要求等。下载链接
根据上述四个数据集的类别分布分析得出:这些数据集大部分都存在类别不平衡的问题,即不同类别的图片数量差异较大。这可能会导致训练出的模型更倾向于识别图片数量大的类别,而对于图片数量较少的类别,识别的可能性较小或者准确率较低。但是上述问题不太会出现在ImageNet数据集中,ImageNet数据集中的类别数量比较平均,数量最大的类为“考拉”,一共有2469张,数量最小的类为“手推车”,也有624张。但是ImageNet中数量第二的类别为“手推车”,这可能会导致另外一个问题:现实世界的物体检测场景中,“考拉”“手推车”等物体并不是最受欢迎的,相较于此,“人”“树木”“车”等物体出现的频率可能更高。这中数据集分布于现实场景仍存在差异,这也是目前无法解决的问题。
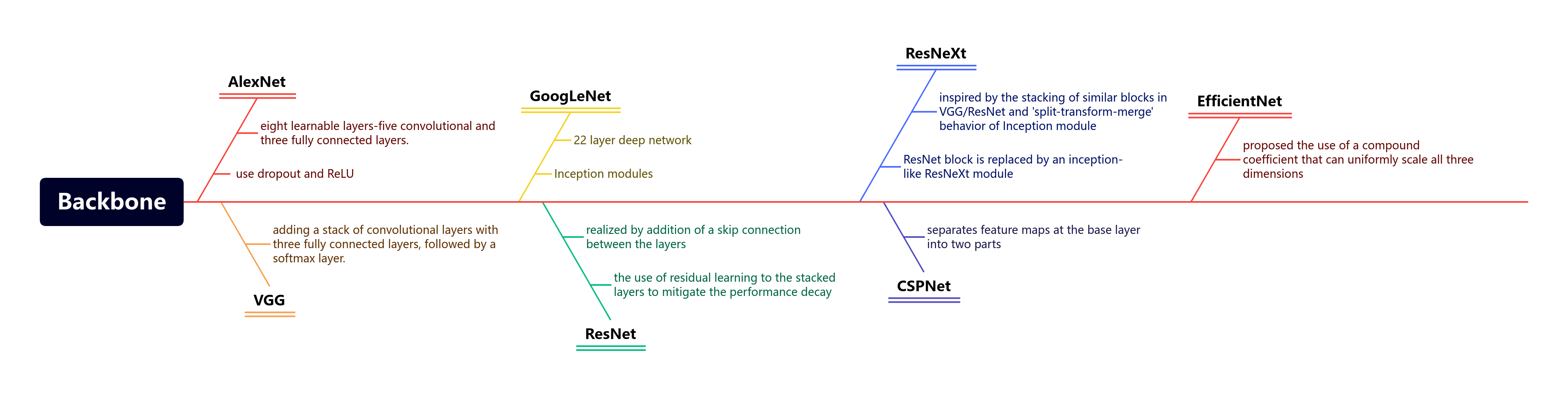
3. Backbone
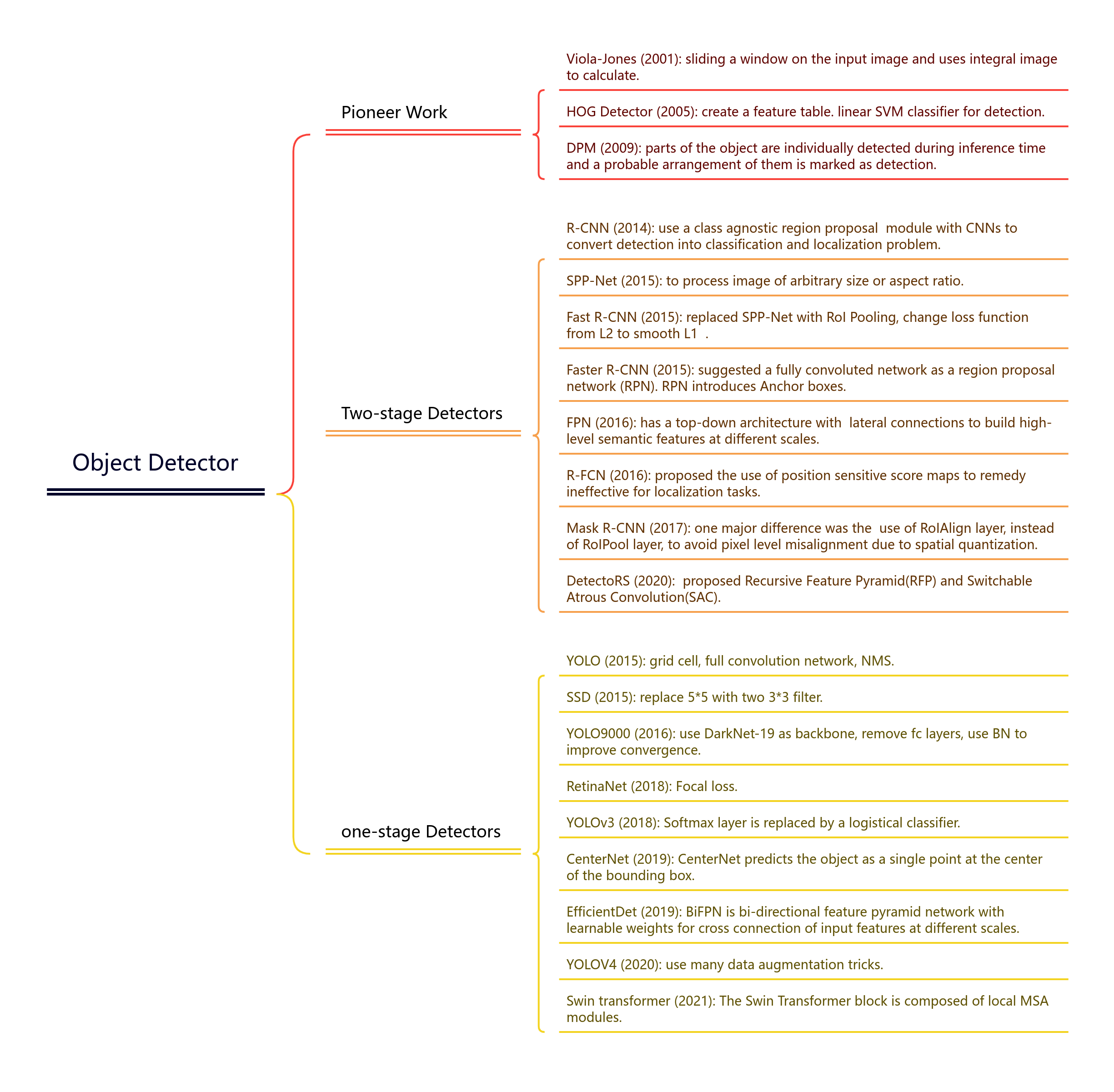
4. Object detectors
5. Breakpoint
本文后续还有关于轻量目标检测模型的介绍、各个检测器对比的结果、未来趋势的展望。
但是,笔者意图做目标检测的简单介绍。感兴趣的读者可以点击此处查看全文。遂作此断点,未来再读。

