Camouflaged Object Detection 阅读笔记
0. Summary
伪装目标检测(Camouflaged object detection,COD)旨在对几乎完全融入周围环境的目标进行识别。该问题的主要难点在于:待检测目标与周围背景具有极高的内在相似性。本文为了解决这样一个问题,提出了名为COD10K的伪装目标检测数据集,并针对该数据集,提出了 Search Identification Network (SINet) 网络模型。该网络模型在包括COD10K以及其他测试数据集上与其他最新的目标检测模型做对比实验,实验结果优于其他所有模型。
1. Introduction
伪装目标检测大概需要做什么工作或者实现什么效果呢?如图1.1,第一行数据来自于COD10K数据集,第二行就是需要实现的检测效果。可以很清楚的看出,文章做的工作其实就是对于图片中一些边界与背景具有高相似度的物体进行识别或者分割。

本文主要贡献:
-
提出了COD10K数据集,专门用于COD。该数据集包括了10K张图片,目标类别包括78种水生、飞行、两栖动物、地面动物。其中每张图片的伪装目标都分层次地进行了标注,标注内容包括类别(category)、边界框(bounding-box)、对象等级(object-level)和实例等级(instance-level)。
-
通过对比COD10K和其他两个现有的数据集,本文提供了12个SOTA(state-of-the-art)基线(baseline)的严格评估,使文章中的研究成为最大的COD研究。
-
文章提出了SINet(Search and Identification Net)伪装目标检测框架,整个框架的训练时间仅为1小时,但是却在所有现有COD数据集上达到了SOTA的性能,在深度学习领域开创了首个完整的伪装目标检测的benchmark。
2. Related Work
通过查阅文献,可以将目标大致分类为三种类别:一般目标、突出目标、伪装目标。
-
GOD(Generic Object Detection):
最流行计算机视觉的思想之一中认为一般目标可能是突出的,也可能是伪装的;伪装目标可以被看做是复杂情况的一般目标。典型的GOD任务包括了语义分割和全景分割任务。
-
SOD(Salient Object Detection):
SOD任务旨在识别图片中最突出的(most attention-grabbing)目标,并且分割出它的像素级轮廓。尽管“突出”和“伪装”两个词语的意思是相对立的,但是包含突出目标的图片可以作为伪装目标检测数据集的负样本。
-
COD(Camouflaged Object Detection):
伪装目标分类:伪装图片可以被粗略的分为两类——天然伪装和人工伪装。天然伪装是指动物为了避免被其天敌猎杀从而实现的一种生存技能;人工伪装通常发生在产品的制造过程(缺陷)或者用于游戏、艺术的隐藏信息。
评估矩阵:由于MAE(Mean absolute error)已经被广泛应用于SOD任务中,因此文本也尝试使用MAE作为评估预测图C和真实结果G之间像素级准确率的度量。虽然MAE能够评估误差和错误的数量,但是MAE不能确定错误发生的地方。所以将采用基于人类视觉感知的E-measure来评估整体结果和伪装目标检测的定位精度。同时,由于伪装目标通常有不同的形状,因此还需要一个用于评估结构相似度的度量,本文考虑了S-measure和F-measure作为该任务的度量模型。
3. Proposed Dataset
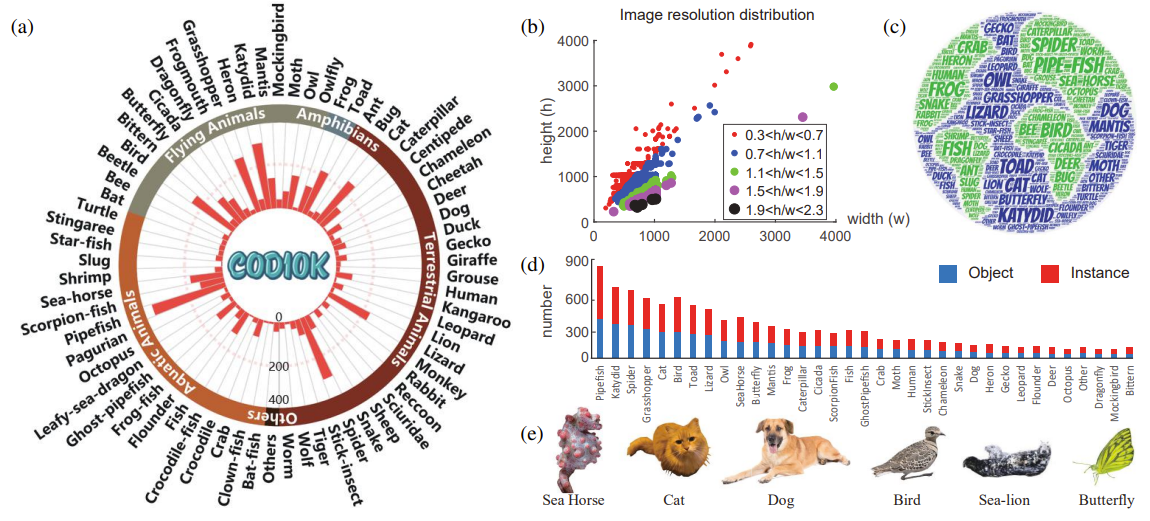
这是一个原文作者提出的一个有10,000张伪装目标图片的数据集COD10K,其中的数据大部分来自Flicker(笔者注:笔者这里怀疑是作者的笔误,并没有名为Flicker的图片网站,应该是Flickr。),其余的图片(大概200张)来自于其他网站。同时为了避免选择偏差(selection bias),该数据集还搜集了3,000张突出目标图片,1,934张非伪装目标图片。关于数据集COD10K的具体细节如图3.1所示,(a)图表示了分类学系统及其直方图分布,(b)图代表了数据集中的图像分辨率分布,(c)图表示了词云分布,即标签中所用词语的地理分布,(d)图表示了不同类别的Object/Instance的数量分布,(e)图展示了一些子类。
关于Object和Instance的区分:作者强调现有的COD数据集主要聚焦在object-level上,然而能够一个对象解析为它的实例对于计算机视觉研究者们是否能够编辑或者理解一个场景来说是至关重要的。因此,作者进一步在实例级(instance-level)上标注了数据集。
标注完成之后,从COD10K数据集中的每个子类中总共随机挑选6000张图片作为训练集,4000张图片作为测试集。
4. Proposed Framework
4.1 Overview
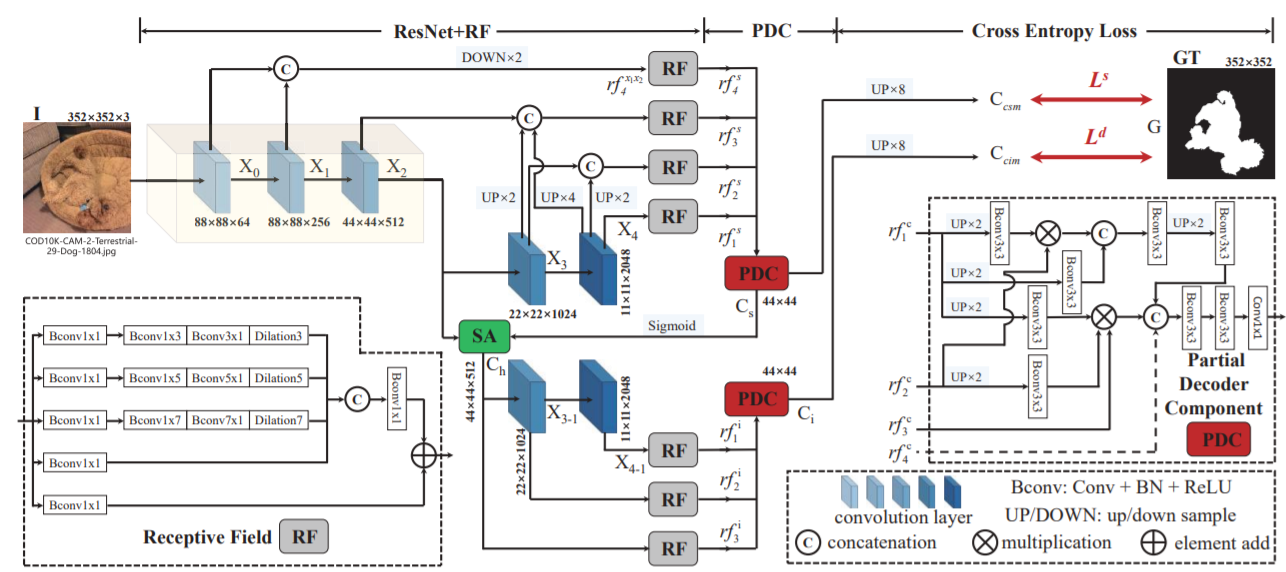
文中提出的SINet框架主要由**Search Module(SM)和Identification Module(IM)**两个模块组成,其中SM模块负责寻找伪装目标,IM模块主要负责对伪装目标的位置进行精确定位。SINet的框架模型如图4.1所示,其中的具体模块的解释将在一下两个部分介绍。
4.2 Search Module(SM)
4.2.1 Bconv(Conv+BN+ReLu)
Bconv是由Convolution、Batch Normalization(BN)和ReLu激活函数共同组成的一个卷积层,其中BN通过将数据标准化,能够加速权重参数的收敛。ReLu作为激活函数,其形式如图4.2所示。从图中不难看出,ReLu函数将所有的负值变为0,而所有的正值都不变,这种操作叫做单侧抑制。
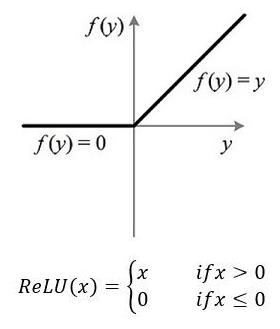
4.2.2 Receptive Field(RF)
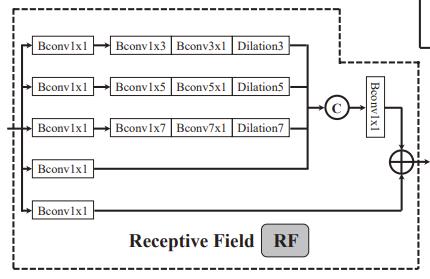
感受野(RF)组件包括了五个分支,如图4.3。在每个分支的第一个卷积层均有32个尺寸为1*1的卷积核,目的是为了将原图在不改变分辨率的前提下将图像通道减少到32个。并且,前三个分支后紧连着两个卷积层,紧接着前三个分支后都紧跟着不同尺寸的空洞卷积层,然后将卷积后的结果与第四个分支的结果进行连接操作之后使用一个Bconv层进行卷积,最后将第五个分支的结果与卷积之后的结果加起来作为RF模块的输出。
SM模块做的工作主要是通过使用不同层次的特征和RF模块,初步定位图像中伪装目标的位置。也就是论文原文里提到的猎人定位猎物位置的那一步。接下来就要使用IM模块来对伪装目标的轮廓进行识别,即对目标进行精确定位。
4.3 Identification Module(IM)
SM(Identification Module)模块的作用对应于文中提到的猎人对目标进行精准定位的部分。在这个部分中提到了两个组件,一个是PDC(Partial Decoder Component),通过阅读论文,笔者认为PDC模块是将SM模块的功能组件进行了集成之后的一个功能模块。首先PDC模块是将RF模块的一些输出通过PDC模块得到一个输出Ccsm。另外一个模块是基于注意力机制提出的SA(Search Attention),SA模块的输入为X2层的特征和PDC组件的输出经过Sigmoid激活函数的结果,联合这两个输入,通过注意力机制消除无关特征的干扰,然后通过RF组件扩大感受野,最终得到另一个输出Ccim。
得到上述两个输出Ccsm和Ccim之后,使用交叉熵损失函数对这两个输出结果进行训练,得到最终的训练模型。
5. Benchmark Experiment
5.1 Experimental Settings
本文中的实验部分训练集采用了CAMO、COD10K和CAMO+COD10K+EXTRA,其中CAMO和COD10K使用数据集中的默认训练集;测试集使用了CHAMELEON数据集和CAMO、COD10K的测试集。关于Baseline方面,由于没有公开可用的基于深度网络的COD模型,所以文中基于以下三个标准选取了12个深度学习baselines:(1)经典模型,(2)最近发表的模型,(3)在某个特定领域达到SOTA表现的模型,例如GOD和SOD。这些选取到的模型都用建议的参数设置进行了训练。
5.2 Results and Data Analysis
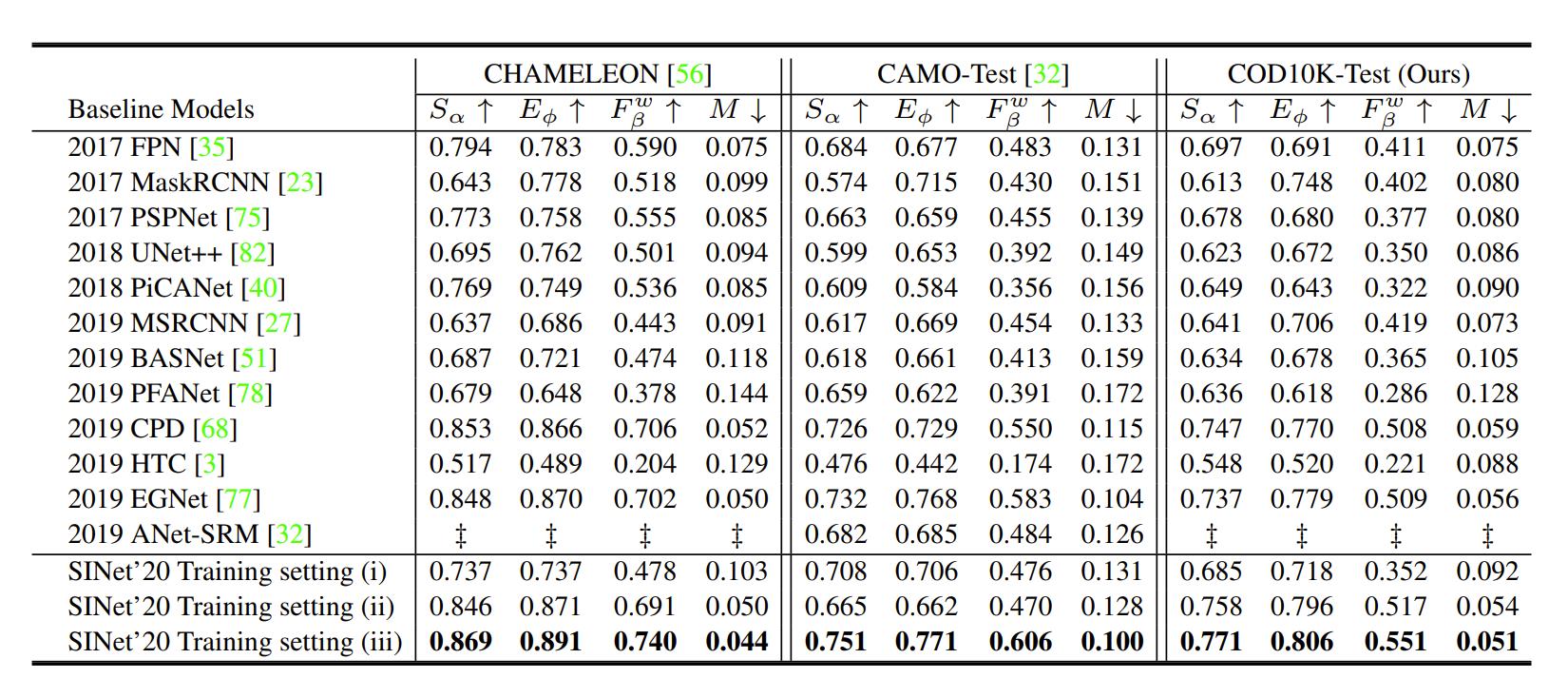
SINet以及文中选取的12个模型在CHAMELEON、CAMO-Test、COD10K-Test上的测试结果如图5.1所示,可以很明显的看出,在三个测试数据集上,SINet的表现均优于其他模型。特别地,GOD模型(如FPN)的表现比SOD模型(如CPD、EGNet)要更差一些,表明SOD框架可能更加适用于COD任务。但是,相比于SOD和GOD模型,SINet显著降低了训练时长(比如:SINet训练一小时,而EGNet则需要训练48小时)且还能在所有数据集上达到SOTA的表现,这说明SINet可能是COD问题的一个有希望的解决方法。
5.3 Cross-dataset Generalization
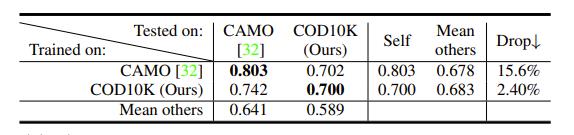
由于数据集的普遍性和难度在训练或者评估不同算法的时候起着至关重要的作用,因此文中实验部分还采用了Cross-dataset Generalization(跨数据集泛化),其思路是:在一个数据集上训练模型,在其他数据集上进行测试。具体操作为:从CAMO和COD10K两个数据集中随机选取800张图片作为训练集,200张图片作为测试集。为了公平起见,作者在每个数据集上训练SINet直到loss稳定。结果如图5.2所示,其中“Self”是指训练和测试在同一个数据集上,“Mean Others”表示除了自己以外其他的平均分(这里用到的训练集和测试集的设置与图5.1中的设置不同,所以不具有性能可比性)。图上结果表明,COD10K的确是最复杂的,因为该数据集有大量的具有挑战性的伪装目标检测图。
5.4 Qualitative Analysis
如图5.3,为SINet与另外两个baseline算法的定性比较结果。可以看到的是,PFANet虽然能定位伪装目标的位置,但是输出不够精确。EGNet由于使用了边界特征,能够比PFANet更好的定位边界,但是仍然会丢失一些细小的细节,比如第一行中的鱼。对于不确定的边界,遮挡和小物体这些具有挑战性的例子,SINet能通过细节推测出伪装目标的位置,进一步说明了模型的健壮性。

6. Potential Applications
COD潜在的应用场景文中提到了:医学图像分割、野外搜救或者嵌入图搜索引擎。
7. Conclusion
本文提出了极具贡献意义的数据集COK10K和COD领域的新baseline——SINet框架。在今后的工作中,作者计划扩展COD10K数据集,提供各种形式的输入,例如RGB-D伪装目标检测(类似于RGB-D显著目标检测等等)。新技术如弱监督学习、Zero-shot Learning、VAE和多尺度主干网络都会探索。

